IQ 192의 o3는 전기양의 꿈을 꾸는가?

IQ 192의 o3는 전기양의 꿈을 꾸는가?
1. 소개#
최근 openai에서 o3 모델을 발표 했다. 그리고 내용이 매우 뜨겁다. arc-agi-pub 테스트에서 인간을 아득히 뛰어 넘었다. 다음이 o3 발표에서 공개한 주요 내용이다.
• 코딩 능력: SWE-Bench Verified에서 71.7% 정확도를 달성했으며, Codeforces에서 2727 ELO 점수를 기록했습니다.
• 수학적 추론: 미국 수학 경시대회(AIME) 벤치마크에서 96.7%의 정확도를 달성하여 이전 모델(o1)의 83.3%를 크게 상회했습니다.
• 시각적 추론: ARC-AGI 벤치마크에서 고성능 설정으로 87.5%의 정확도를 달성했으며, 이는 인간 수준의 성능을 넘어선 결과입니다.
그리고 코딩 테스트 결과(codeforfces 2727 elo 점수)를 토대로 다음과 같은 어그로성 이미지가 돌아다니기 시작했다.
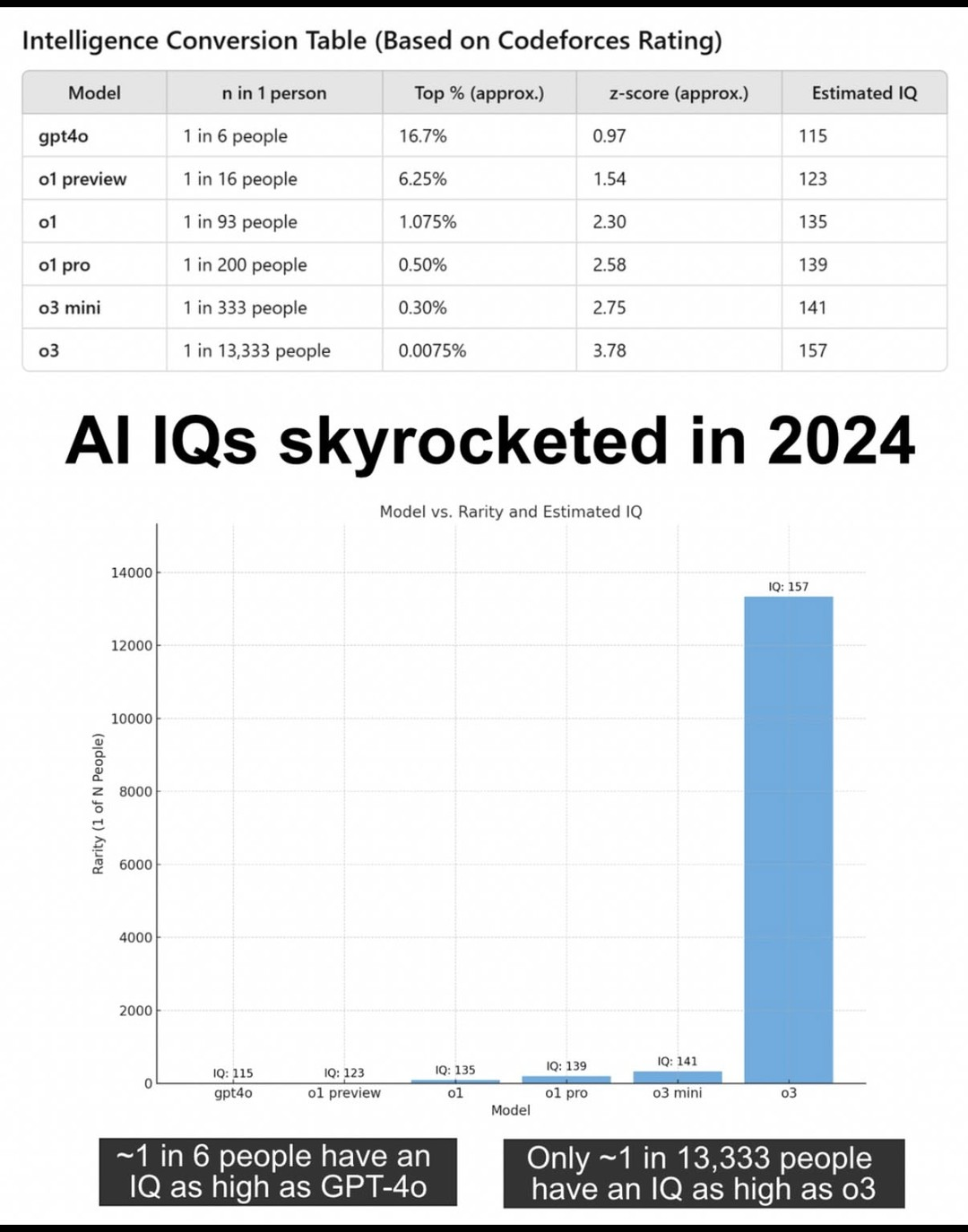
그러니까 한 코딩 테스트 elo 사이트에서 O3가 2700점을 받았는데 이게 상대적으로 인간 기준으로 상위 0.0075%고 이를 IQ 점수로 환산한 테이블이다. 157이 뭐 대수냐라고 할수 있겠지만 여기 나온 지능 수치 157은 멘사에서 사용하는 표준편차24가 아니라 표준편차15기준이므로 이를 멘사에서 쓰는 기준으로 변경하면 191.2다. 비록 이것이 과장된 표현이라고 하더라도, o3의 성능이 상당히 높다는 것은 분명하다. 그리고 이 글에서는 해당 arc-agi-pub 벤치마크에 대해 분석한 블로그 글을 하나 소개하고 그에 대해 고찰해보기로 한다.
이 글은 현존하는 “LLM들의 문제는 사실 추론(reasoning)이 아니라 지각(perception)에 있는 것 아니냐”는 통찰, 그리고 이를 극복하는 방법에 대한 아이디어를 담아보려 한다.
2. openai o3의 ARC-AGI-Pub 벤치마크 분석#
트위터에서 다음의 글을 봤다. 이 단락은 이 글에 대해 AI로 요약한 글이다.
Why do pre-o3 LLMs struggle with generalization tasks like @arcprize? It's not what you might think.
— Mikel Bober-Irizar (@mikb0b) December 24, 2024
OpenAI o3 shattered the ARC-AGI benchmark. But the hardest puzzles didn’t stump it because of reasoning, and this has implications for the benchmark as a whole.
Analysis below🧵 pic.twitter.com/NF5Uca2UTr
블로그 원본: https://anokas.substack.com/p/llms-struggle-with-perception-not-reasoning-arcagi
2.1. ARC란 무엇인가#
- ARC(Abstraction and Reasoning Corpus): 원래 프랑소와 쇼레(François Chollet)가 고안한, 인간 수준의 직관적 추론을 테스트하기 위한 벤치마크. 작은 2D 격자 안에서 색깔, 패턴, 규칙 변환 등을 학습해야 하는 퍼즐 형태로 구성.
- ARC-AGI-Pub: 최근 ARC의 변형·확장판으로, AGI 측면을 좀 더 체계적으로 평가하고자 마련된 데이터셋. 문제 크기(그리드 픽셀 수)가 다양한 것이 특징.
2.2. OpenAI의 o3 모델 성능#
- 최근 OpenAI가 발표한 o3 모델이 ARC-AGI-Pub에서 400개 문제 중 366개를 풀어내며 주목받음.
- 이전 세대 모델들(o1, o1-mini 등)은 문제의 크기가 커질수록 성능이 급격히 떨어졌는데, o3는 그 한계를 크게 확장해 4096 픽셀 정도의 문제까지는 처리 가능해 보임.
2.3. LLM들의 “크기 한계” 문제#
- 글쓴이는 o3가 풀지 못한 문제들을 살펴본 결과, LLM들이 2D 격자 크기가 커질수록 (즉, 입력 픽셀이 늘어날수록) 출력 실수나 잘못된 연산을 내놓는 패턴을 발견.
- 이전 세대 모델들은 512픽셀 이상에서 이미 난항을 겪었고, o3가 그 한계를 4096픽셀로 끌어올리긴 했지만, 그 이상으로는 여전히 문제가 발생.
- 이 현상은 사람과 대조적임. 사람은 그리드가 커져도 정답률이 크게 변하지 않음(“크기”가 아니라 추론해야 하는 연산이 더 어려운지 여부가 중요).
2.4. LLM의 근본적 한계: 1D 토큰 vs 2D 문제#
- ARC 문제는 본질적으로 2D 추론을 요함. 행과 열을 오가며 객체를 파악하고, 변환 규칙을 학습해야 함.
- 반면 LLM은 1D 토큰 시퀀스로 입력과 출력을 처리. 행/열 간 정보를 묶어서 다루려면 토큰이 멀리 떨어져 있어야 하며, 그만큼 맥락 길이가 길어져서 실수가 잦아짐.
- 예: 30×30 격자를 텍스트로 나열하면 무려 900(혹은 공백 포함 1800 이상) 토큰을 일일이 맞춰 출력해야 하는데, 중간에 한 줄이라도 빼먹으면 오답 처리.
2.5. 실제 실험 예시#
- 저자는 같은 난이도의 문제를 그리드만 확장(각 행과 열을 복제)해 입력하면, 이전 모델(o1-mini 등)은 원래 문제는 풀면서도 확장된 문제는 거의 풀지 못하는 현상을 확인.
- 이는 LLM이 “규칙을 일반화”하지 못해서라기보다는, 그리드가 커지면 토큰 수가 폭발적으로 늘어나 제대로 “지각(perception)”하거나 “정렬(alignment)”하지 못하기 때문이라는 분석.
2.6. 시사점#
- 기존 LLM들의 고유한 추론 능력은 사실 과소평가되었을 가능성이 있음. 텍스트 형태로 2D 정보를 다루는 데 어려움이 컸기 때문.
- o3의 성능이 매우 뛰어난 것은 임계점(threshold effect) 때문일 수도 있음. 기존보다 훨씬 큰 2D 픽셀을 한 번에 처리할 수 있게 되었으나, 그 이상으로 확장하면 여전히 취약함.
- 사람처럼 2D(또는 멀티모달) 정보를 자연스럽게 다루는 체계가 아니면, ARC 같은 2D 문제에선 언제든 한계를 보일 수 있음.
2.7. 참고 문헌#
- H-ARC 논문: 사람을 대상으로 ARC 문제를 풀게 한 실험에서, 인간은 문제 크기보다 문제 자체의 변환 난이도 때문에 오답이 많았다는 분석을 제시.
- Perceiver 모델 [1]: DeepMind가 개발한 멀티모달 Transformer 구조로, 다양한 형태(시각·청각·언어)의 입력 데이터를 단일 구조 안에서 처리 가능하게끔 설계.
- Judea Pearl의 3단계 인과추론 [2]: 단순 상관관계(1단계)를 넘어 개입(2단계)과 반사실(3단계)에 기반한 추론이 필요함을 제시. 현재 LLM들은 대부분 1단계에 머물러 있다는 지적.
3. AGI를 만들기위한 3+1가지 핵심 아이디어#
내가 생각하고 있는 핵심 아이디어는 다음과 같다.
-
1 “인간 처럼” 동적으로 감각 정보의 해상도를 원하는 부분만 올려서 받을 수 있어야 한다.
-
2 “인간 처럼” 텍스트가 아니라 이미지와 소리 정보를 같이 받아 처리 해야한다.
-
3 (지극히 개인적인 사고실험으로 나온 생각) “인간 처럼” 시스템1과 시스템2 2개의 모델로 이루어져야 한고 실시간 훈련이 가능해야 한다.
-
4 그리고 또 “지극히 사고 실험만 해본 개인적인 생각”: “인간 처럼” 주기적으로 뇌의 정보를 비슷한 데이터끼리 정렬하는, 일종의 하드디스크 defragmentation 같은 기능이 있어야한다고 생각한다. 인간이 잠을 자는 이유와 피로감이 인간이 낮시간에 보고 들은 새로운 정보들이 선별적으로 쓸모 없다고 여기는 뇌의 부분 부분에 뇌에 뒤죽 박죽으로 저장되었기 때문이라고 생각한다.
(참고로 3번, 4번은 필자의 개인적인 사고 실험의 결과이므로 이에 대해서는 충분히 비판적인 시각으로 받아들이기 바란다.)
3.1. AI가 어려워하는 것은 “추론”이 아니라 “퍼셉션”#
- 핵심 주장: ARC에서 LLM이 실패하는 주된 이유는 추론 능력 자체가 부족해서가 아니라, 문제를 1D 토큰으로 “지각”하는 데 제한이 있기 때문.
- 사람이 ARC를 풀 때는 2D 이미지를 직관적으로 “묶어서” 인식하지만, LLM은 긴 토큰 열을 일일이 문장 형태로 소화해야 함.
- 이 때문에 실제로는 충분히 추론할 수 있는 내용도, 결정적으로 토큰을 맞추지 못하거나 2D 전역 구조를 놓치는 바람에 실패한다는 것.
3.2. “사람처럼” 하면 되지 않을까?#
- 인간 시각 시스템은 중심 시야(고해상도)와 주변 시야(저해상도)가 구분되어 있음. 필요하면 시선을 옮겨 고해상도로 보고, 나머지는 대충 훑음.
- 이를 AI에도 적용한다면, 처음부터 모든 픽셀을 초고해상도로 한꺼번에 처리하는 대신, 관심 있는 부분만 고해상도로, 나머지는 저해상도로 받으면 어떨까?
- 이렇게 “주의(attention)”를 시각적으로 구현해, 토큰 폭발을 막고 핵심 영역만 정밀 추론하면, 지금보다 훨씬 적은 연산으로 강력한 결과를 낼 수 있을 것. 같은 양의 연산을 한다면 가량 o3만큼의 연산 자원을 사용한다면 o3보다 훨씬 더 높은 성능을 낼 수 있을 것이다.
3.3. 텍스트 모델의 한계와 멀티모달 접근#
- “텍스트만으로는 본질적으로 한계가 있다”는 주장. 인간 수준 지능을 위해서는 음성, 시각 등 멀티모달 입력을 통합해야 함.
- 특히 ARC처럼 2D 구조가 중요한 과제에서 텍스트 변환은 비효율적. LLM 내부를 아무리 키워도 토큰으로 모든 픽셀을 다루는 것은 부담이 큼.
- “Perceiver” 같은 모델들은 시각·청각·언어 등 다양한 입력을 하나의 Transformer 구조로 통합 처리 가능하므로, 이 방향이 AGI 연구에 힌트를 줄 수 있음.
3.4. “선택적 집중”이 곧 지능#
- 사람도 주변 잡음(소리·시각 정보·신체 신호 등)을 대거 걸러내고, 현재 초점에 필요한 정보만 강하게 처리함. 몰입할 때는 심지어 배고픔이나 주변 소음조차 안 들림.
- AI도 이렇게 **‘선택적 집중(Selective Attention)’**을 구현해, 무의미한 픽셀·토큰을 무작정 다 스캔하지 않고 필요한 부분에 집중한다면, 적은 자원으로 더 높은 성능을 낼 수 있을 것.
- 이는 AGI가 어떤 하드웨어·소프트웨어 환경에서 구현되든, 궁극적으로 “중요한 것에 주의를 주고, 불필요한 것엔 자원을 덜 쓰는” 구조가 필요함을 시사.
3.5. 더 큰 컨텍스트 윈도우가 정답일까?#
- 단순히 LLM의 컨텍스트 윈도우를 엄청나게 늘려서(예: 수십만~수백만 토큰) 모든 정보를 한 번에 처리가 가능해지면, 문제 해결력이 높아질 수는 있음.
- 하지만 이는 계산 자원이 기하급수적으로 늘어난다는 점에서 비효율적이고, 인간처럼 “필요할 때 보고 싶은 부분만 고해상도로 처리”하는 접근이 더 합리적일 거란 의견.
3.6. AGI로 가는 길#
- ARC 실험은 LLM이 2D 정보를 “제대로 지각”하는 데 어려움을 겪음을 보여주며, 이는 곧 “멀티모달 + 주의(attention) + 인지 구조의 유연성”이 필요함을 시사.
- 이와 관련해, UCLA의 주디아 펄(Judea Pearl) 교수는 AI가 단순 상관관계에서 벗어나 인과추론(개입과 반사실적 사고)으로 가야 한다고 주장[2].
- ARC 같은 2D 문제를 제대로 다루려면, 먼저 “시각적 퍼셉션” 자체가 사람 수준으로 정교해져야 하고, 그다음 추론 단계를 인과적으로 확장해야 한다는 큰 그림을 그려볼 수 있음.
- 그리고 대니얼 카너먼의 “생각에 관한 생각(Think slow and fast)“에서 제시한 시스템1과 시스템2의 모델을 사용하여 실시간 훈련이 가능한 시스템. 즉, 작은 시스템1 모델만 큰 시스템2 모델을 이용하여 실시간으로 훈련 시킨다.
4. 결론 및 참고 자료#
정리하자면, o3의 ARC-AGI-Pub 벤치마크에서 드러난 LLM의 한계는 “2D 문제를 1D 텍스트로 지각하는 어려움”에서 비롯된 면이 크다는 분석이다. 이를 두고 일부에서는 “LLM의 추론 능력 부족”이라고 보기도 하지만, 사실은 “지각(perception) 문제”가 더 큰 비중을 차지한다는 것.
참고 문헌 및 자료#
- Jaegle, A., et al. (2021). Perceiver: General perception with iterative attention. International Conference on Machine Learning (ICML).
- Pearl, J. (2018). Theoretical impediments to machine learning with seven sparks from the causal revolution. arXiv preprint arXiv:1801.04016.
- ARC 원본 벤치마크: F. Chollet. (2019). On the measure of intelligence. arXiv preprint arXiv:1911.01547.
- H-ARC 관련 정보: H-ARC: Human ARC Dataset (각 ARC 문제를 기계 학습뿐 아니라 다수의 사람에게 풀게 해본 연구)