인지 부하가 중요하다. (번역)

코딩에서의 인지 부하와 그 중요성#
좋은 글을 발견해서 번역해본다. 사실 요즘 코딩 자체에 대한 기술에 대해서 흥미가 1도 없는데, 이 글은 사람 뿐만 아니라 AI가 코드를 읽고 작성할 때에도 영향을 받는 중요한 내용이라고 생각한다.
인지 부하란 무엇인가
-
인간이 한 번에 작업 기억(working memory)에 저장하고 처리할 수 있는 정보의 양에는 한계가 있다. 코드가 복잡하면 머릿속에 여러 조건이나 흐름을 계속 기억해야 하므로 인지 부하가 높아지고, 이로 인해 개발 속도가 떨어지고 실수가 늘어난다.
-
코드를 읽는 데 있어 인지 부하(cognitive load)가 중요한 역할을 한다는 점은 “학습과 문제 해결 과정에서 인지 부하가 커질수록 이해와 유지보수가 어려워진다”는 인지 부하 이론(Cognitive Load Theory) 연구들에서 자주 나타난다.
이 글의 대한 나의 논리는 다음과 같다.
- 개발 업무에서 최소 60%-80%의 시간이 코드를 읽는 시간이다.
- 코드를 읽는 시간에 가장 큰 영향을 미치는 것은 인지 부하다.
- 사람 뿐 아니라 AI도 이러한 인지 부하를 겪는다. (검증되지 않은 개인적인 의견)
- 그러므로 인지 부하를 이해하고 인지 부하를 줄이는 코드를 작성하는 것이 중요하다.
영어 원문은 이 링크에서 확인할 수 있다.
“무엇보다 중요한 것은 인지 부하다”#
이 로고 이미지는 Reddit에서 가져왔습니다.
이 문서는 계속 업데이트되는 자료이며(마지막 업데이트: 2024년 12월), 여러분의 기여를 환영합니다!
소개#
수많은 유행어와 모범 사례가 있지만, 대부분 실패했습니다. 우리는 더 근본적이고 결코 틀릴 수 없는 무언가가 필요합니다.
가끔 코드를 읽다 혼란을 느끼는데, 이 혼란은 시간과 돈이 듭니다. 혼란은 높은 인지 부하 때문입니다. 이건 추상적인 개념이 아니라 실제로 느껴지는 인간의 기본적 한계입니다.
코드를 작성하는 것보다 읽고 이해하는 데 시간을 훨씬 많이 쓰므로, 우리는 코드를 통해 과도한 인지 부하를 만들어내지 않는지 계속 확인해야 합니다.
인지 부하#
인지 부하는 개발자가 작업을 완료하기 위해 머릿속에서 처리해야 하는 정보의 양입니다.
코드를 읽을 때, 변수 값이나 제어 흐름 로직, 호출 순서 등을 기억합니다. 보통 사람은 이런 정보를 한 번에 대략 4개 정도만 머릿속에 담을 수 있습니다. 이 한계를 넘으면 이해하기가 훨씬 어려워집니다.
예를 들어, 완전히 낯선 프로젝트에 수정 요청을 받았다고 합시다. 이 프로젝트는 매우 똑똑한 개발자가 만들었고, 온갖 멋진 아키텍처와 라이브러리, 트렌디한 기술이 쓰였습니다. 즉, 우리에게 높은 인지 부하를 안겨준 것입니다.
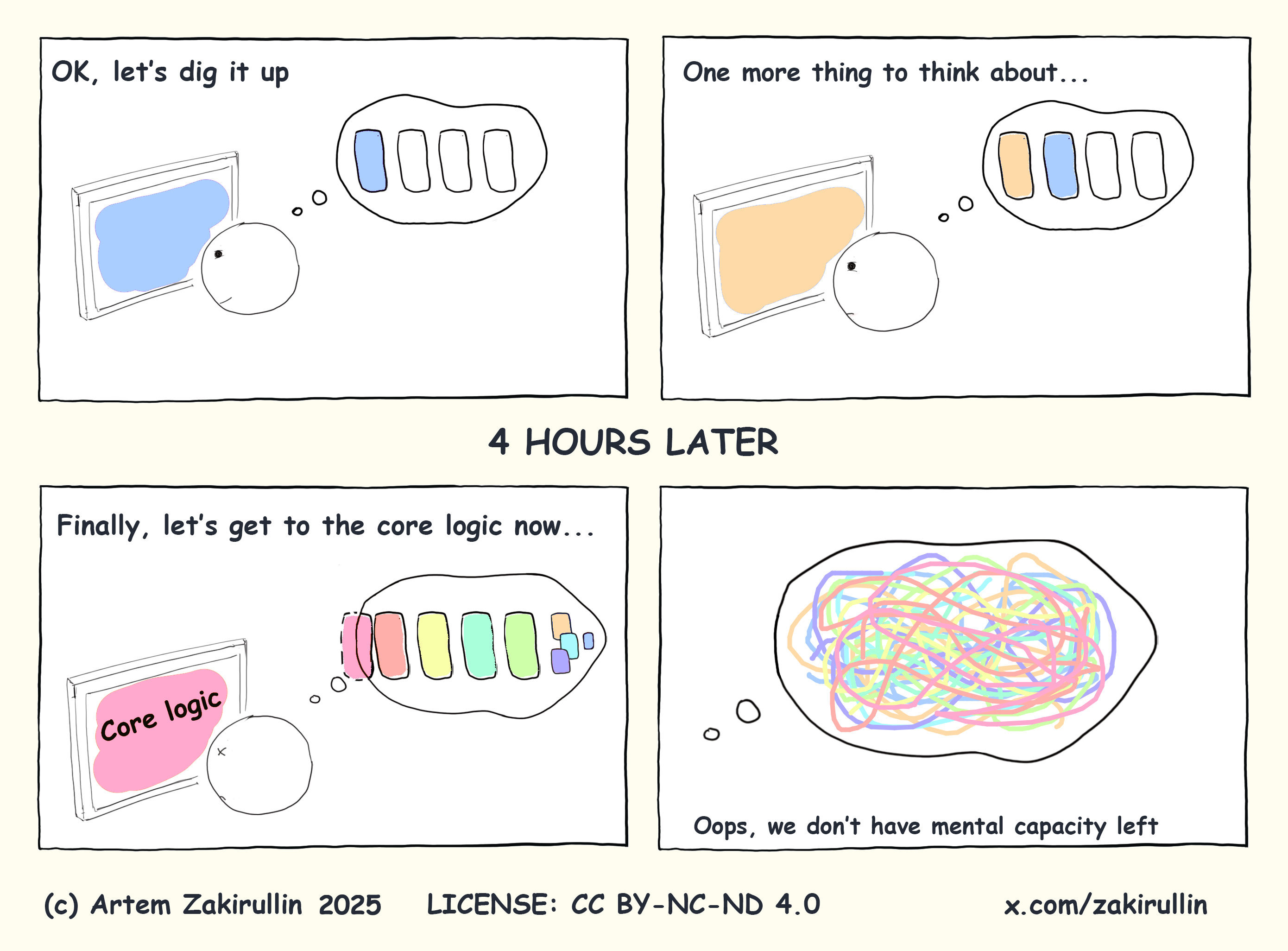
가능한 한 인지 부하를 줄여야 합니다.
인지 부하의 유형#
-
내재적(Intrinsic): 과제 자체의 난이도 때문에 생기는 인지 부하로, 소프트웨어 개발의 본질적 복잡도입니다. 줄일 수 없습니다.
-
과잉(Extraneous): 정보가 제시되는 방식 때문에 생깁니다. ‘스마트한 개발자’의 특이한 습관처럼 과제와 직접 관련 없는 요소가 원인입니다. 크게 줄일 수 있으며, 여기 집중해야 합니다.
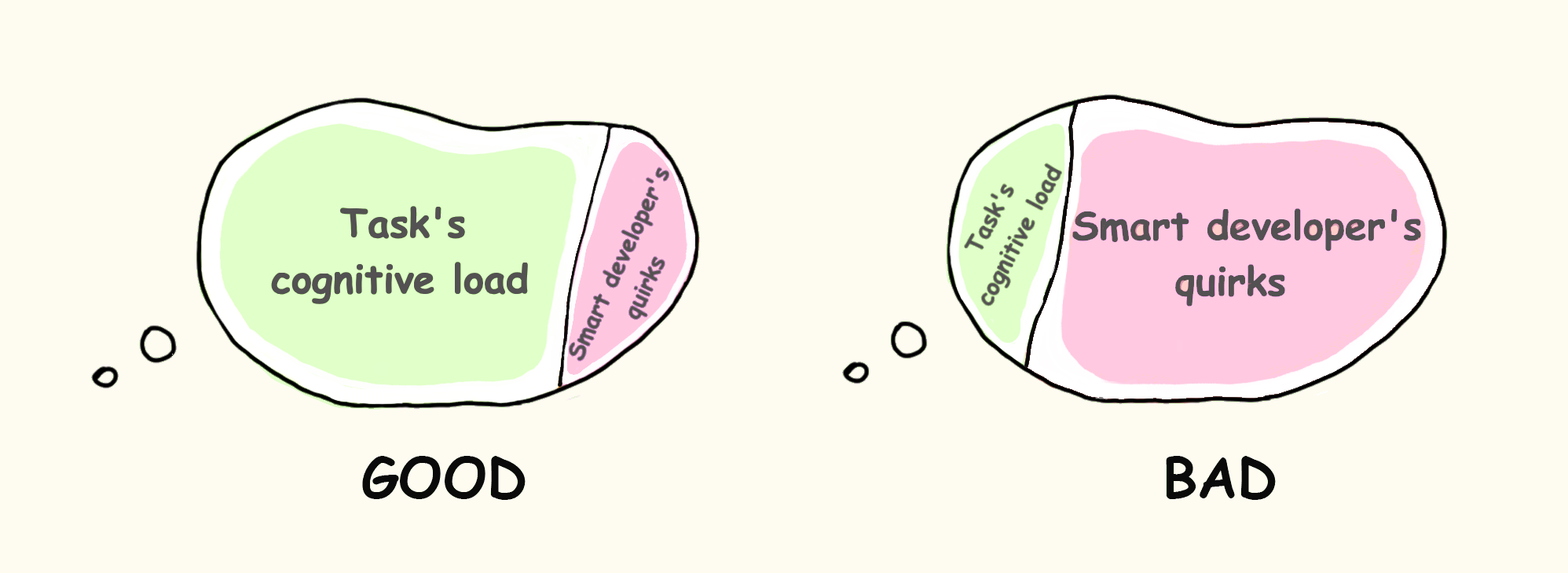
구체적 예시로 들어가 봅시다.
구체적 예시로 들어가 봅시다.
이 글에서는 인지 부하의 정도를 다음과 같이 표현하겠습니다.:
- 🧠: 작업 기억이 새 상태, 인지 부하가 없음
- 🧠++: 이미 2개의 사실을 머리에 담고 있어 인지 부하가 늘어남
- 🤯: 4개 이상의 사실을 한꺼번에 기억해야 하는 정신적 과부하 상태
물론 뇌는 훨씬 복잡하지만, 단순화해서 생각해봅시다.
복잡한 조건문#
if val > someConstant // 🧠+
&& (condition2 || condition3) // 🧠+++, 이전 조건이 참이면서 condition2나 condition3 중 하나는 참이어야 함
&& (condition4 && !condition5) { // 🤯, 이 시점에는 혼란이 가중됨
...
}
중간 변수로 의미를 분명히 하면 좋습니다:
isValid = val > someConstant
isAllowed = condition2 || condition3
isSecure = condition4 && !condition5
// 🧠, 이제 조건 자체를 기억할 필요 없이, 변수 이름만 보면 됨
if isValid && isAllowed && isSecure {
...
}
중첩 if#
if isValid { // 🧠+, 유효한 입력에만 적용되는 코드
if isSecure { // 🧠++, 유효하고 보안이 맞는 상태
stuff // 🧠+++
}
}
아래처럼 초기에 조건을 만족하지 않으면 일찍 반환(early return)하면,
if !isValid
return
if !isSecure
return
// 🧠, 이전 조건들을 더 이상 기억할 필요가 없음
stuff // 🧠+
행복 경로(happy path)에 집중하기만 하면 되므로 작업 기억을 덜 소모합니다.
상속 지옥#
관리자 관련 기능을 조금 수정해달라는 요청을 받았다고 합시다: 🧠
AdminController extends UserController extends GuestController extends BaseController
아, 기능 일부가 BaseController에 있군요: 🧠+
기본 역할(롤) 로직은 GuestController에 있네요: 🧠++
UserController에서 부분적으로 바뀐 것도 확인해야 합니다: 🧠+++
마지막으로 AdminController를 보고 코드를 작성하려 하는 순간: 🧠++++
그런데 ‘SuperuserController’가 ‘AdminController’를 상속하네요. AdminController를 수정하면 상속받는 클래스를 깨뜨릴 수도 있으니, SuperuserController도 봐야 합니다: 🤯
상속보다는 합성을 선호하세요. 자세한 내용은 이미 많으니 생략합니다.
너무 잘게 나눈 메서드, 클래스, 모듈#
메서드, 클래스, 모듈은 여기서 같은 개념으로 봅시다.
“메서드는 15줄 이하가 좋다”거나 “클래스는 작을수록 좋다” 같은 ‘만트라’는 어느 정도 틀렸습니다.
- 깊은 모듈(Deep module): 인터페이스는 단순하지만, 내부 구현이 복잡해 많은 기능을 제공
- 얕은 모듈(Shallow module): 제공 기능은 미미하지만, 인터페이스가 상대적으로 복잡
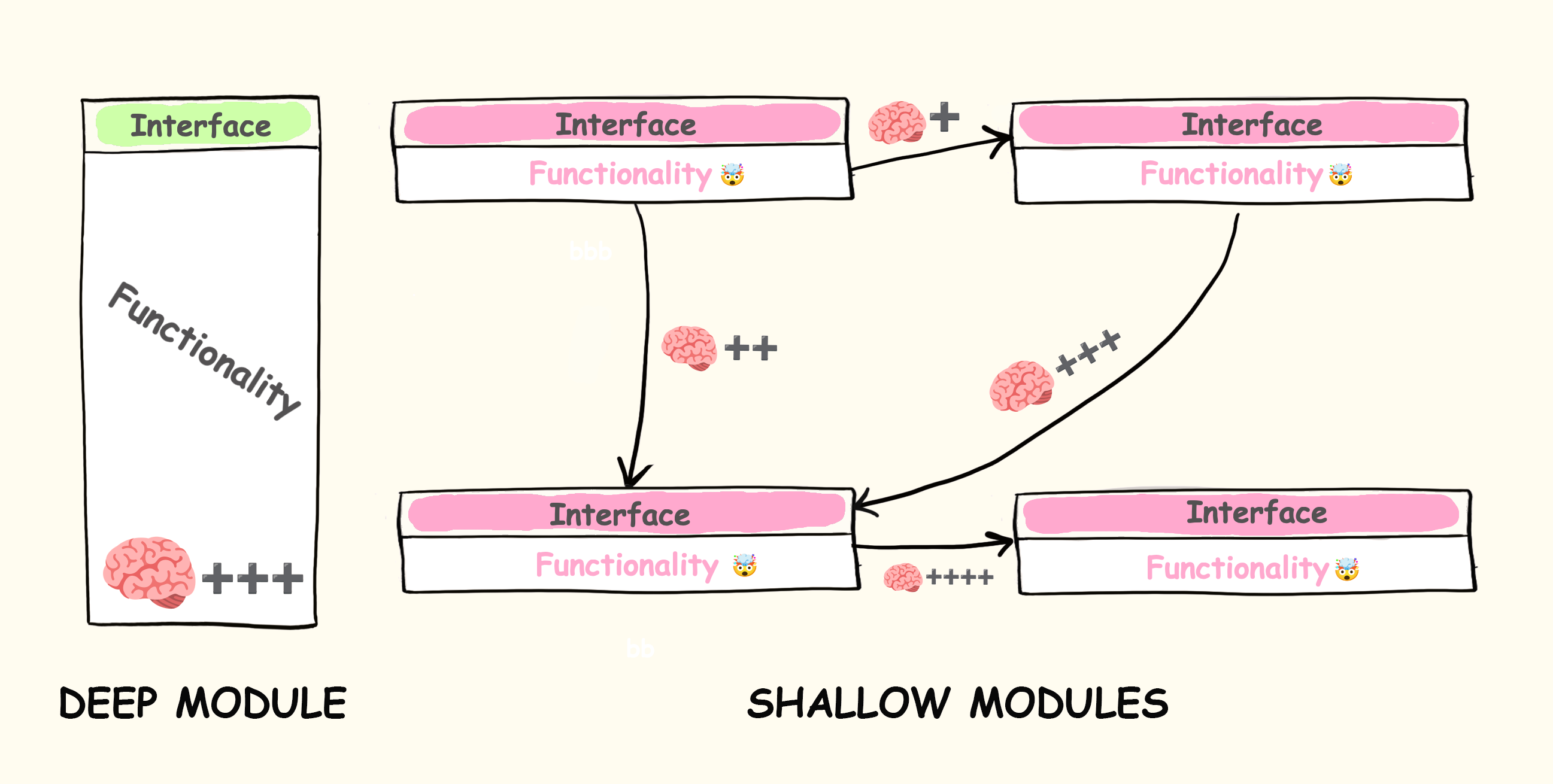
얕은 모듈이 너무 많으면 프로젝트를 이해하기 어렵게 합니다. 각 모듈의 책임뿐 아니라 모듈간의 상호작용도 머리에 넣어야 합니다. 얕은 모듈의 목적을 이해하려면 관련 모듈을 모두 이해 해야 합니다. 🤯
숨겨야 할 복잡성이 제대로 숨겨지지 않아, 유지보수가 더 힘들어집니다.
5천 줄 정도의 개인 프로젝트를 두 개를 가지고 있습니다. 하나는 80개의 얕은 클래스, 다른 하나는 7개의 깊은 클래스로 구성됩니다. 1년 반 뒤 다시 돌아왔을 때, 80개로 나뉜 프로젝트는 클래스 간 상호작용을 다 복원해야 해서 인지 부하가 매우 컸지만, 7개의 깊은 클래스로 구성된 쪽은 이해하기 쉬웠습니다.
“최고의 컴포넌트는 강력한 기능을 제공하면서도 인터페이스가 단순한 것이다”
- John K. Ousterhout
UNIX I/O 인터페이스는 매우 단순합니다. 다섯개의 함수로 이루어져있습니다.
open(path, flags, permissions)
read(fd, buffer, count)
write(fd, buffer, count)
lseek(fd, offset, referencePosition)
close(fd)
이 함수들의 현대 내부 구현은 수십만 줄일 만큼 복잡합니다. 복잡성은 모두 내부에 감춰져 있습니다. 그래서 쉽게 사용할 수 있습니다.
이 깊은 모듈 예시는 John K. Ousterhout가 쓴 A Philosophy of Software Design에서 가져온 것입니다. 이 책은 소프트웨어 개발에서의 복잡성의 핵심을 다룰 뿐만 아니라, Parnas가 쓴 영향력 있는 논문 On the Criteria To Be Used in Decomposing Systems into Modules도 최고의 해석을 제공하고 있습니다. 두 자료 모두 필수적으로 읽어야 합니다. 추가로 참고할 만한 글들: It’s probably time to stop recommending Clean Code, Small Functions considered Harmful.
P.S. 만약 우리가 책임이 너무 많은 “비대해진(God) 객체”를 옹호한다고 생각한다면, 그것은 잘못된 것입니다.
얕은 모듈과 단일 책임 원칙(SRP)#
우리는 종종 “모듈은 하나의 일만 책임져야 한다”라는 모호한 원칙을 따르다가, 얕은(shallow) 모듈을 아주 많이 만들어 버리곤 합니다. 그런데 그 “한 가지 일”이라는 것은 정확히 무엇일까요? 객체를 인스턴스화하는 것 자체도 한 가지 일이겠죠? 그렇다면 MetricsProviderFactoryFactory는 괜찮아 보인다는 말인가요. 이런 클래스들의 이름과 인터페이스는 구현 전체보다도 정신적으로 더 부담스러워지기 쉬운데, 이게 도대체 무슨 추상화일까요? 어딘가 잘못되었습니다.
이렇게 얕은 컴포넌트들 사이를 오가며 작업하는 것은 정신적으로 피로를 줍니다. 선형적 사고(linear thinking)는 인간에게 더 자연스럽습니다.
우리는 사용자와 이해관계자들의 요구를 만족시키기 위해 시스템을 변경합니다. 우리는 그들에게 책임을 집니다.
모듈은 한 명의(그리고 오직 한 명의) 사용자나 이해관계자에게만 책임져야 합니다.
이것이 바로 이 단일 책임 원칙(Single Responsibility Principle)의 핵심입니다. 간단히 말해, 어떤 한 곳에서 버그를 만들었는데 두 명의 서로 다른 비즈니스 담당자가 동시에 와서 불만을 제기한다면, 우리는 원칙을 어긴 것입니다. 이 원칙은 모듈 안에서 하는 일의 개수와는 전혀 상관이 없습니다.
하지만 이 해석조차도 때로는 득보다 실이 많을 수 있습니다. 이 규칙은 사람 수만큼이나 다양한 방식으로 이해될 수 있기 때문입니다. 더 나은 접근법은 모든 것이 만들어내는 인지 부하(cognitive load)가 어느 정도인지 살펴보는 것입니다. 한 모듈에서의 변경이 다른 여러 비즈니스 흐름 전체에 연쇄 반응을 일으킨다는 걸 기억하는 것은 정신적으로 부담스럽습니다. 결국 딱 그 정도가 핵심입니다.
너무 많은 얕은 마이크로서비스들#
이 얕은-깊은(shallow-deep) 모듈 원칙은 규모와 무관하며, 마이크로서비스 아키텍처에도 적용할 수 있습니다. 얕은 마이크로서비스가 너무 많아도 소용이 없습니다. 업계는 어느 정도 “매크로서비스(macroservices)”—즉, 너무 얕지 않은(=깊은) 서비스를 향해 가는 추세입니다. 이 중 가장 최악이자 고치기 어려운 현상 중 하나는, 과도하게 잘게 쪼개진 얕은 분리가 종종 만들어내는 “분산 모놀리식(distributed monolith)”입니다.
제가 예전에 어떤 스타트업을 자문한 적이 있는데, 5명짜리 개발 팀이 17(!)개의 마이크로서비스를 도입했습니다. 그들은 일정을 10개월이나 넘기고도 아직 출시 준비가 전혀 안 된 상태였습니다. 새로운 요구사항이 생길 때마다 4개 이상의 마이크로서비스를 수정해야 했습니다. 통합 영역에서의 진단 난이도는 폭증했습니다. 시장 출시 시간(time to market)도 인지 부하도 둘 다 용납할 수 없을 정도로 높아졌습니다. 🤯
새로운 시스템의 불확실성에 이렇게 대처하는 것이 옳은 방식일까요? 초반에는 올바른 논리적 경계를 도출하기가 엄청나게 어렵습니다. 핵심은 가능한 한 늦게, 책임감 있게 기다릴 수 있는 시점까지 결정을 미루는 것입니다. 왜냐하면 그 시점에야 비로소 결정을 내리는 데 가장 많은 정보를 갖게 되기 때문입니다. 네트워크 계층을 처음부터 도입해버리면, 설계 결정을 처음부터 되돌리기 어렵게 만듭니다. 그 팀의 유일한 정당화는 “FAANG 기업들이 마이크로서비스 아키텍처가 효과적임을 증명했다”였습니다. 이봐요, 현실감 없이 큰 꿈만 꾸지 말아야 합니다.
Tanenbaum-Torvalds 논쟁에서는, 리눅스의 모놀리식(monolithic) 설계가 결함이 있고 시대에 뒤떨어졌으니 마이크로커널 아키텍처를 사용해야 한다고 주장했습니다. 확실히 이론적, 미학적 관점에서 마이크로커널 설계가 더 우수해 보였습니다. 그러나 실용적인 면에서—30년이 지난 지금도 마이크로커널 기반 GNU Hurd는 여전히 개발 중이며, 모놀리식 리눅스는 어디에나 존재합니다. 이 페이지도 리눅스로 구동되고, 여러분의 스마트 티포트도 리눅스로 구동됩니다. 모놀리식 리눅스로 말이죠.
진정으로 격리된 모듈로 잘 구성된 모놀리식은, 여러 마이크로서비스 집합보다 대개 훨씬 유연합니다. 또한 유지보수에도 훨씬 적은 인지 노력이 듭니다. 오직 배포를 분리해야만 하는 상황(예: 개발 팀 규모 확장)에서만 모듈 간에 네트워크 계층(미래의 마이크로서비스)을 추가하는 것을 고려하면 됩니다.
Feature-rich languages#
우리는 좋아하는 언어에 새로운 기능이 추가되면 신이 납니다. 그 기능들을 배우고, 그 위에 코드를 작성하기도 합니다.
만약 기능이 정말 많다면, 몇 줄 안 되는 코드를 다루면서도 “이 기능, 저 기능 중 어떤 것을 쓸까” 고민하느라 30분을 쓸 수 있습니다. 이는 어느 정도 시간 낭비일 수 있습니다. 하지만 더 안 좋은 건, 나중에 돌아와서 다시 그 생각 과정을 재현해야 한다는 점입니다!
우리는 단지 이 복잡한 프로그램을 이해하는 것만이 아니라, “사용 가능한 기능들 중 왜 어떤 프로그래머가 이런 식으로 접근하기로 결정했는지”도 이해해야 합니다. 🤯
이 말들은 바로 Rob Pike가 한 것입니다.
선택지의 수를 제한해 인지 부하를 줄이세요.
언어 기능은, 서로 독립적(orthogonal)인 한에서는 괜찮습니다.
20년간 C++를 다뤄온 엔지니어의 생각 ⭐️
저는 얼마 전 RSS 리더를 보다가 “C++” 태그가 달린 읽지 않은 글이 대략 300개 정도 쌓여 있는 걸 봤습니다. 작년 여름 이후로는 언어에 대한 글을 단 하나도 읽지 않았고, 그래서 기분이 좋습니다!
저는 지금까지 20년 동안 C++을 사용해 왔는데, 제 인생 거의 3분의 2에 해당합니다. 그중 대부분의 경험은 언어의 가장 어두운 구석들(예: 온갖 형태의 정의되지 않은 동작들)을 다루는 것이었어요. 이건 재사용하기 어려운 경험이며, 이제 그걸 다 내던져야 한다고 생각하니 좀 소름이 돋기도 합니다.
예를 들어,
requires ((!P<T> || !Q<T>)) 안의 || 토큰은 “제약 조건의 논리합(constraint disjunction)”을 의미하고, requires (!(P<T> || Q<T>)) 안의 ||는 예전부터 쓰이던 “논리 OR 연산자”인데, 이 둘은 서로 다르게 동작합니다.여러분은 그냥 사소한 타입(trivial type)을 위해 공간을 할당해두고, 그곳에
memcpy로 일련의 바이트를 복사해 넣는 것만으로는(추가 작업 없이) 객체의 생애가 시작되지 않는다는 것을 알고 계셨나요? 예전 C++20 이전에는 그랬습니다. C++20에서 이 문제는 고쳐졌지만, 언어의 인지 부하는 오히려 늘었어요.복잡성이 해결되었다 해도, 인지 부하는 끊임없이 증가합니다. 무엇이 언제 고쳐졌는지, 그리고 예전엔 어땠는지를 전부 알아야 하니까요. 어쨌든 저는 전문가니까요. 물론 C++은 레거시 지원이 뛰어납니다. 이것은 곧 여러분이 그 레거시를 반드시 마주하게 된다는 뜻이기도 합니다. 예를 들어, 지난달 제 동료 중 한 명은 C++03에서의 어떤 동작에 대해 제게 물었습니다.
🤯초기화 방법이 20가지 있었는데, 통합 초기화 구문(uniform initialization)이 추가되었습니다. 이제 21가지가 되었네요. 그런데 이니셜라이저 리스트에서 생성자를 고르는 규칙을 혹시 기억하나요? 정보 손실이 가장 적은 암시적 변환에 관한 내용이 있었는데, 만약 그 값이 정적으로 알려진다면...
🤯이렇게 늘어나는 인지 부하는 현재의 업무 과제 때문이 아닙니다. 도메인이 본질적으로 복잡해서 생긴 것도 아니죠. 역사의 산물로 인해 단지 거기에 존재할 뿐(과잉 인지 부하)입니다.
저는 몇 가지 규칙을 세워야 했습니다. 예컨대 “그 한 줄의 코드가 명백해 보이지 않고, 표준을 기억해야 한다면, 난 그렇게 쓰지 않는 편이 낫겠다”라는 식이죠. 참고로 표준은 대략 1500페이지쯤 됩니다.
제가 C++을 탓하려는 건 결코 아닙니다. 저는 그 언어를 사랑해요. 다만 이제 좀 피곤하네요.
감사합니다. 0xd34df00d가 작성한 글을 인용했습니다.
비즈니스 로직과 HTTP 상태 코드 반환#
백엔드에서는 다음과 같이 반환합니다:
401은 만료된 jwt 토큰403은 권한이 충분하지 않음418은 차단된 사용자
프론트엔드 팀은 백엔드 API를 사용해 로그인 기능을 구현합니다. 그들은 잠시나마 이런 인지 부하를 머릿속에 만들어야 합니다:
401은 만료된 jwt 토큰임 //🧠+, 알았어, 임시로 기억해두자403은 권한 부족임 //🧠++418은 차단된 사용자임 //🧠+++
프론트엔드 개발자들은 (바라건대) 나중에 기여하는 사람들도 이 매핑을 다시 생각해낼 필요가 없도록, numeric status -> 의미의 사전을 각자 쪽에서 만들겠죠.
그 뒤 QA 팀이 등장합니다: “어, 403 상태를 받았는데, 이게 토큰 만료인가 권한 부족인가?”
QA 팀은 바로 테스트를 시작할 수 없습니다. 먼저 백엔드 쪽에서 한 번 만들어진 그 인지 부하를 다시 재현해야 하기 때문입니다.
왜 이런 맞춤형 매핑을 작업 기억에 간직하고 있어야 할까요? HTTP 전송 프로토콜에서 업무 세부사항을 분리하고, 응답 본문에 스스로를 설명하는 코드를 직접 돌려주는 편이 낫습니다:
{
"code": "jwt_has_expired"
}
프론트엔드 쪽에서의 인지 부하: 🧠 (새로움, 기억할 사실 없음)
QA 쪽에서의 인지 부하: 🧠
동일한 규칙은 (데이터베이스든 다른 어디든) 모든 숫자 상태에도 적용됩니다. 자의 설명적인(self-describing) 문자열을 선호하세요. 우리는 메모리가 640K였던 시대에 살고 있지 않습니다.
사람들은
401과403사이에서 논쟁하며, 각자 머릿속의 모델을 기반으로 결정합니다. 새 개발자가 들어오면, 그 사람도 다시 그 사고 과정을 재구성해야 합니다. 여러분은 “왜 이런 결정을 했는가”를 기록한 ADR(Architecture Decision Record)을 남겨서 신입들이 이해하도록 도울 수도 있습니다. 하지만 결국 말이 안 됩니다. 사용자 관련 에러와 서버 관련 에러를 구분할 수는 있겠지만, 그 외에는 좀 흐릿합니다.
P.S. “authentication”과 “authorization”을 구분하는 것 역시 정신적으로 부담될 때가 많습니다. “login”과 “permissions” 같은 더 단순한 용어를 사용해 인지 부하를 줄일 수 있습니다.
DRY 원칙의 과도한 적용#
“Do not repeat yourself”는 소프트웨어 엔지니어로서 처음 배우는 원칙 중 하나입니다. 우리는 몇 줄의 코드라도 중복된다는 사실을 견디기 힘들 정도로 이 원칙이 깊이 새겨져 있습니다. 일반적으로 훌륭하고 근본적인 규칙이지만, 과도하게 쓰이면 우리가 감당할 수 없는 인지 부하를 만들어냅니다.
오늘날 모든 사람들은 논리적으로 분리된 컴포넌트를 기반으로 소프트웨어를 만듭니다. 그 컴포넌트들은 종종 여러 개의 코드베이스에 분산되어 있으며, 각 코드베이스가 별도의 서비스를 나타내기도 합니다. 중복을 없애려고 애쓰면, 관련 없는 컴포넌트끼리 강력하게 얽히게 될 가능성이 있습니다. 그 결과 한 부분에서의 변경이, 겉보기에는 전혀 관련 없어 보이던 영역들에서 예기치 않은 결과를 초래할 수 있습니다. 또한 개별 컴포넌트를 교체하거나 수정하는 능력도 전체 시스템에 영향을 주지 않고는 불가능해질 수 있습니다. 🤯
사실 똑같은 문제는 단일 모듈 안에서도 발생합니다. 장기적으로 보이지도 않는 유사성에 기반해 너무 이른 시점에 공통 기능을 추출하려고 하면, 쓸데없이 수정·확장하기 어려운 추상화를 낳을 수 있습니다.
Rob Pike는 한 번 이렇게 말했습니다:
A little copying is better than a little dependency.
우리는 바퀴를 재발명하지 않으려는 유혹이 너무 강해, 직접 쉽게 작성할 수 있는 작은 함수를 쓰기 위해서도 거대한 라이브러리를 통째로 가져오고 싶어집니다.
여러분의 모든 의존성(dependencies)은 곧 여러분의 코드입니다. 가져온 라이브러리의 10단계 넘는 스택 트레이스를 따라가며 무슨 일이 잘못됐는지(무조건 문제가 생기기 마련이죠) 알아내는 것은 고통스럽습니다.
Tight coupling with a framework#
프레임워크에는 “마법”이 많습니다. 프레임워크에 지나치게 의존하면, 앞으로 합류하는 모든 개발자는 그 “마법”부터 배워야 합니다. 몇 달이 걸릴 수도 있습니다. 프레임워크는 MVP를 며칠 만에 출시하게 해주지만, 장기적으로는 쓸데없는 복잡성과 인지 부하를 더해버리는 경향이 있습니다.
설상가상으로, 어느 시점에서 프레임워크가 새로운 요구사항에 맞지 않으면 큰 제약으로 작용할 수 있습니다. 거기서부터 사람들은 결국 프레임워크를 포크 떠서 자체 버전을 유지하게 됩니다. 신규 입사자가 어떤 가치를 제공하려면 (즉, 이 커스텀 프레임워크를 배우려면) 쌓아야 하는 인지 부하를 상상해 보세요. 🤯
우리는 결코 모든 것을 처음부터 직접 만들라고 주장하는 게 아닙니다!
우리는 어느 정도 프레임워크에 구애받지 않는(framework-agnostic) 방식으로 코드를 작성할 수 있습니다. 비즈니스 로직은 프레임워크 내부가 아니라, 프레임워크의 컴포넌트를 “활용”해야 합니다. 프레임워크를 코어 로직의 바깥에 두세요. 프레임워크를 일종의 라이브러리처럼 사용하십시오. 이렇게 하면 새로운 기여자들이 첫날부터 가치를 더할 수 있습니다. 굳이 프레임워크 관련 복잡성의 잔해를 먼저 헤쳐갈 필요 없이 말이죠.
Layered Architecture#
이 모든 것에는 어떤 엔지니어링적 흥분감이 있습니다.
저는 한때 Hexagonal/Onion 아키텍처의 열렬한 옹호자였습니다. 여기저기 도입해 보았고, 다른 팀들에게도 장려했습니다. 그 결과 프로젝트의 복잡성은 올라갔고, 단지 파일 개수만 해도 2배로 늘었습니다. 글루 코드(glue code)를 엄청나게 많이 작성하고 있다는 느낌도 들었죠. 요구사항이 자꾸 바뀌니 여러 겹의 추상화 레이어 전부를 수정해야 했고, 정말 지겨워졌습니다. 🤯
추상화는 복잡성을 숨기기 위한 것인데, 여기서는 그냥 간접층(indirection)을 늘릴 뿐입니다. 문제를 빨리 해결하려면 호출을 따라가며 뭘 잘못했는지, 뭘 놓쳤는지를 파악해야 하는데, 이 아키텍처에서는 레이어가 분리되어 있어서 실패 지점에 도달하기까지, 자주 서로 이어지지 않는 여러 단계를 기하급수적으로 밟아야 합니다. 매 단계가 우리 제한된 작업 기억에 차지하는 공간은 🤯입니다.
이 아키텍처는 처음에는 직관적으로 말이 되는 것 같았지만, 실제로 프로젝트에 적용할 때마다 득보다 실이 훨씬 컸습니다. 결국 우리는 좋게 말해 “오래된” 의존성 역전 원칙(dependency inversion principle)을 택하고 나머지는 다 포기했습니다. 포트/어댑터(port/adapter) 같은 용어는 배울 필요도 없고, 쓸데없는 수평 추상화 레이어도 없으며, 과잉 인지 부하도 없습니다.
만약 이런 레이어링이 DB나 다른 의존성을 빨리 교체하도록 해줄 거라고 생각한다면, 그건 착각입니다. 스토리지를 바꾸는 일은 온갖 문제가 생기며, 우리 말을 믿으세요—데이터 접근 레이어를 위한 추상화 정도는 걱정거리 중 가장 작은 축에 속합니다. 최대한 좋게 봐줘도, 추상화로 겨우 마이그레이션 시간의 10% 정도(그마저도 있을지 모르지만)를 절약할 수 있을 뿐이고, 실제 고통은 데이터 모델 호환성, 통신 프로토콜, 분산 시스템의 문제, 그리고 암묵적 인터페이스 등에 있습니다.
사용자가 충분히 많은 API라면,
계약서에 무엇을 약속하든 상관없이,
시스템에서 관측 가능한 모든 동작은
누군가에게 의존 대상이 됩니다.
우리는 스토리지를 교체했는데, 그에 10개월이 걸렸습니다. 예전 시스템은 단일 스레드였고, 노출되는 이벤트들도 순차적이었습니다. 우리 모든 시스템이 그 관측된 동작에 의존했습니다. 이 동작은 API 계약에 명시된 것도 아니었고, 코드에 반영된 것도 아니었습니다. 새로운 분산 스토리지는 그걸 보장하지 않았습니다—이벤트가 순서 없이(out-of-order) 나왔습니다. 우리는 새 스토리지 어댑터를 짜는 데 단 몇 시간밖에 안 썼지만, 그 후 10개월은 순서가 뒤섞인 이벤트와 기타 문제들을 처리하느라 보냈습니다. 이제 와서 레이어링이 부품을 빨리 교체하도록 도와준다고 말하긴 우습죠.
그렇다면 미래에 큰 이득도 없는데, 이런 레이어 아키텍처로 높은 인지 부하를 감수할 이유가 뭘까요? 게다가 대부분의 경우, 그 핵심 컴포넌트를 교체할 미래는 절대 오지 않습니다.
이러한 아키텍처들은 근본적인 것이 아니라, 더 근본적인 원칙들의 주관적이고 편향된 결과물일 뿐입니다. 왜 그런 주관적 해석에 의존해야 할까요? 대신 의존성 역전 원칙, 인지 부하, 정보 은닉 같은 근본적인 규칙들을 따르세요. 토론해 보세요.
아키텍처를 위한 아키텍처 차원에서 추상화 레이어를 추가하지 마세요. 실용적인 이유로 확장점(extension point)이 필요할 때만 추가하십시오. 추상화 레이어가 공짜가 아니라, 그것들을 우리 작업 기억에 담아둬야 한다는 사실을 잊지 말아야 합니다.
DDD#
도메인 주도 설계(DDD)는 훌륭한 점들이 있지만, 종종 오해받기도 합니다. 사람들은 “우리는 DDD로 코드를 작성한다”고 말하는데, 사실 DDD는 문제 영역(problem space)에 관한 것이지, 해법 영역(solution space)에 관한 것은 아닙니다.
보편 언어(ubiquitous language), 도메인(domain), 경계(bound), 애그리게이트(aggregate), 이벤트 스토밍(event storming) 등은 전부 문제 영역에 대한 것입니다. 이는 우리가 도메인에 관한 통찰을 배우고 경계를 추출하도록 도와줍니다. DDD는 개발자, 도메인 전문가, 비즈니스 사람들 모두가 하나의 통일된 언어를 사용해 효과적으로 소통하게 해줍니다. 그러나 우리는 이런 문제 공간의 측면보다는, 특정 폴더 구조, 서비스, 리포지토리 같은 해결책 영역에 집중해버리는 경향이 있습니다.
DDD를 우리가 해석하는 방식은 아마도 고유하고 주관적일 가능성이 큽니다. 그리고 만약 이 해석 위에 코드를 쌓아나간다면, 즉 과도한 인지 부하를 만들어낸다면—미래의 개발자들은 망하게 됩니다. 🤯
Examples#
- 우리의 아키텍처는 표준적인 CRUD 앱 아키텍처이며, Postgres 위에 올린 파이썬 모놀리식입니다.
- Instagram은 엔지니어 3명으로 1400만 사용자를 확장했습니다.
- 우리가 “와, 이 사람들 엄청 똑똑하네”라고 생각했던 그 회사들 대부분은 실패했습니다.
- 시스템 전체를 연결하는 하나의 함수가 있을 뿐이죠. 시스템이 어떻게 동작하는지 알고 싶다면—그걸 읽으러 가세요.
이런 아키텍처들은 꽤나 지루하고 이해하기도 쉽습니다. 누구든 큰 정신적 노력 없이 파악할 수 있습니다.
아키텍처 리뷰에 주니어 개발자를 참여시키세요. 그들은 정신적으로 부담스러운 부분들을 찾아내는 데 도움을 줄 것입니다.
익숙한 프로젝트에서의 인지 부하#
문제는 익숙함이 단순함과 같지 않다는 것입니다. 둘 다 정신적 노력이 크게 들지 않는 상태에서 공간을 이동할 때의 “편안함”이라는 느낌은 비슷하지만, 그 이유가 전혀 다릅니다. 여러분이 쓰는 모든 “영리한”(읽기: “자기 도취적”)이자 관용적이지 않은 기교는 다른 이들에게 학습 비용을 부과합니다. 한 번 그 학습을 마치면, 그 코드를 다루는 건 덜 어렵게 느껴지겠죠. 그래서 이미 익숙한 코드를 어떻게 단순화할지 알아채기가 어렵습니다. 저는 “새로 들어온 친구(new kid)”가 그 코드에 너무 익숙해지기 전에 비판해보도록 권장하는 이유가 이것입니다.
아마 이전 작성자들은 이 거대한 난장판을 한 번에 만든 게 아니라, 아주 작은 단위로 점진적으로 누적해온 것일 겁니다. 그래서 여러분은 이걸 한꺼번에 이해하려고 시도해야 했던 첫 번째 사람일 것입니다.
제 수업 시간에, 어느 날 우리는 방대한 SQL 저장 프로시저를 들여다보고 있었는데, 수백 줄의 조건문이 거대한 WHERE 절에 있었습니다. 누군가가 “도대체 어떻게 이렇게까지 되었냐”고 묻길래, 저는 “조건이 2~3개밖에 없을 땐 또 하나 추가해도 별 차이가 없고, 20~30개가 되었을 때는 또 하나 추가해도 별 차이가 없기 때문”이라고 답했습니다.
코드베이스에 작용하는 “단순화 힘”은 여러분이 내리는 의도적 결정 외에는 존재하지 않습니다. 단순화는 노력이 필요하고, 사람들은 너무 자주 바쁩니다.
Dan North에게 감사드립니다.
프로젝트의 정신적 모델(mental models)을 장기 기억으로 내부화했다면, 높은 인지 부하를 겪지 않을 것입니다.
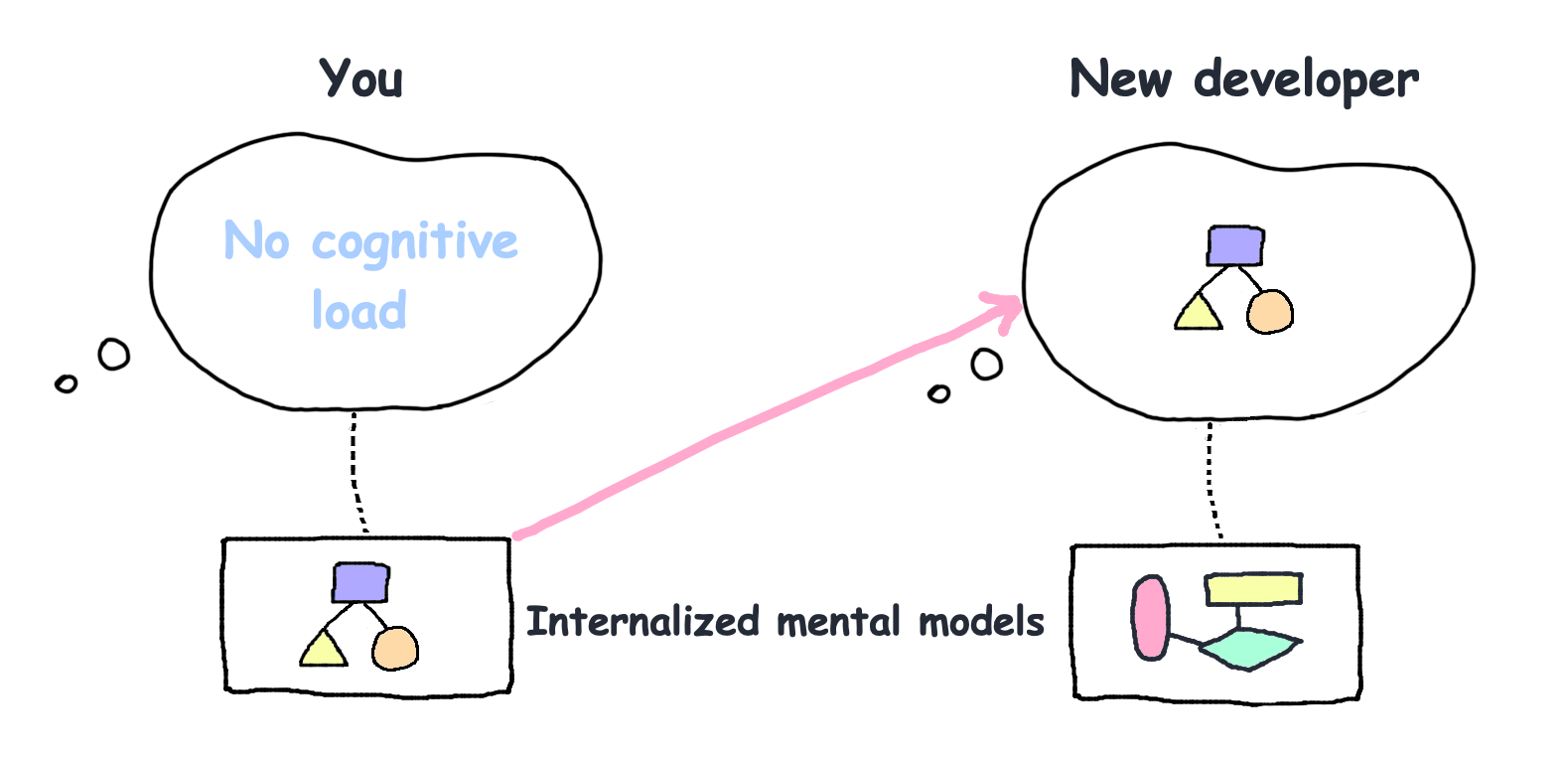
배워야 할 정신적 모델이 많아질수록, 새 개발자가 가치를 만들어내는 데 더 많은 시간이 걸립니다.
프로젝트에 새로운 사람을 합류시킬 때, 그들이 얼마나 혼란스러워하는지 측정해보세요(페어 프로그래밍이 도움될 수 있습니다). 만약 그들이 연속으로 약 40분 넘게 헷갈려한다면—코드를 개선할 부분이 있다는 뜻입니다.
인지 부하를 낮게 유지하면, 사람들은 회사에 입사하고 몇 시간 안에 당신의 코드베이스에 기여할 수 있습니다.
결론#
2장에서 우리가 유추했던 것이 사실이 아니라고 잠깐 상상해봅시다. 그렇다면 우리가 방금 부정한 결론은 물론이고, 이전 장에서 유효하다고 받아들였던 결론들도 옳지 않을 수 있습니다. 🤯
이 느낌이 드시나요? 단순히 글 전체를 헤집고 다니며(얕은 모듈들!), 의미를 파악해야 할 뿐만 아니라, 문단 자체가 전반적으로 이해하기 어렵습니다. 우리는 방금 독자 여러분의 머릿속에 불필요한 인지 부하를 만들어냈습니다. 동료들에게 이런 짓은 하지 맙시다.
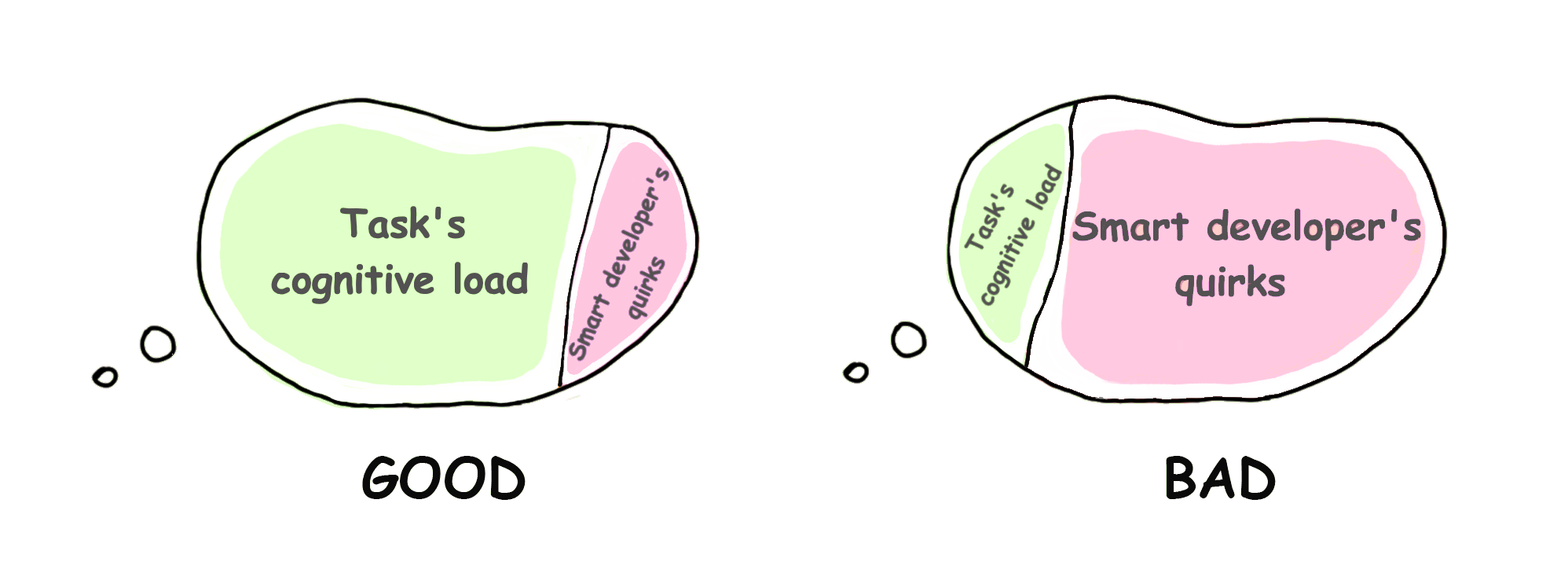
우리는 작업 자체에 내재된 수준 이상의 모든 인지 부하를 줄여야 합니다.
끝.
-
karpathy의 트위터를 보고 읽어보고 내용이 좋아서 번역을 했음.
Nice post on software engineering.
— Andrej Karpathy (@karpathy) December 25, 2024
"Cognitive load is what matters"https://t.co/eMgxu0YgWw
Probably the most true, least practiced viewpoint. pic.twitter.com/RY2rrtk2lJ